Mixture of Experts
Table of contents
An ensemble learning (meta-learning) technique in the field of neural networks.
Note reference: Mixture of Experts
Keywords: MoE, Gating Model, Ensemble Learning, Meta-learning, Divide and Conquer, Stack Generalization
Workflow
- Division of task into subtasks.
- Develop an expert for each task. (Mixture density network)
- Use a gating model to decide which expert to use. (‘Classifier selection algorithm’)
- Use expectation maximization (EM) to train the experts and gating model together. (Gaining dynamic confidence)
- Pool predictions and gating model output to make a prediction.
Relationship with other techniques:
Classification And Regression Trees (CART). As a divide-and-conquer approach. Decision tree. As a hierarchical mixture of experts.
Stacked generalization (stacking). As meta-learning model.
Further readings
Literature review of MoE in 2012: Twenty Years of Mixture of Experts
Improvement of MoE in 2021: Switch Transformers: Scaling to a Trillion Parameter Models with Simple and Efficient Sparsity
Mistral.AI ‘s open-source Mistral 7B Model in 2023: Mistral 7B
Elements
Note reference: Mixture of Experts from HuggingFace.
Sparse MoE layers
The “experts”, where each of them is a neural network, typically FFNs.
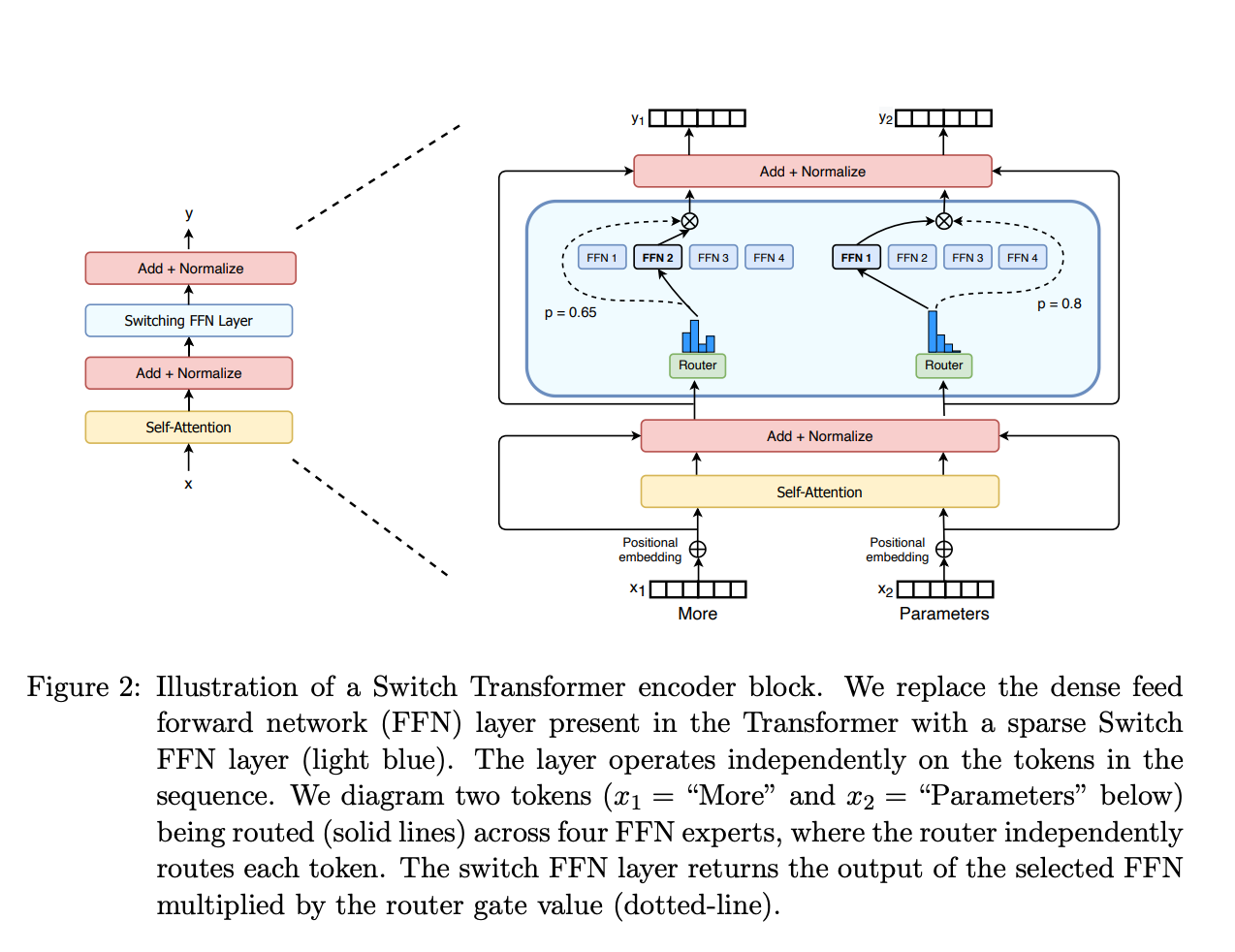
‘Experts’ are sparse Switch FFN layers. Reference: Switch Transformers paper.
Gate network - ‘Router’
Determine which expert to ask. Composed of learned parameters and is pretrained together with experts.
Challenges
- In training: compute-efficient pre-train, but struggles to generalize during fine-tuning and vulnerable to overfitting.
- In inference: Not using all parameters leads to faster inference compared to models with the same number of parameters, but all of the parameters need to be loaded in RAM and thus requires large memory.
Brief History and Some Methods


References in Green
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., & Dean, J. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer.
Lepikhin, D., Lee, H., Xu, Y., Chen, D., Firat, O., Huang, Y., Krikun, M., Shazeer, N., & Chen, Z. (2020). GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding.
Zoph, B., Bello, I., Kumar, S., Du, N., Huang, Y., Dean, J., Shazeer, N., & Fedus, W. (2022). ST-MoE: Designing Stable and Transferable Sparse Expert Models.