From UI automation agents to Screen understanding
Table of contents
再探 Accessibility-UI automation framework.
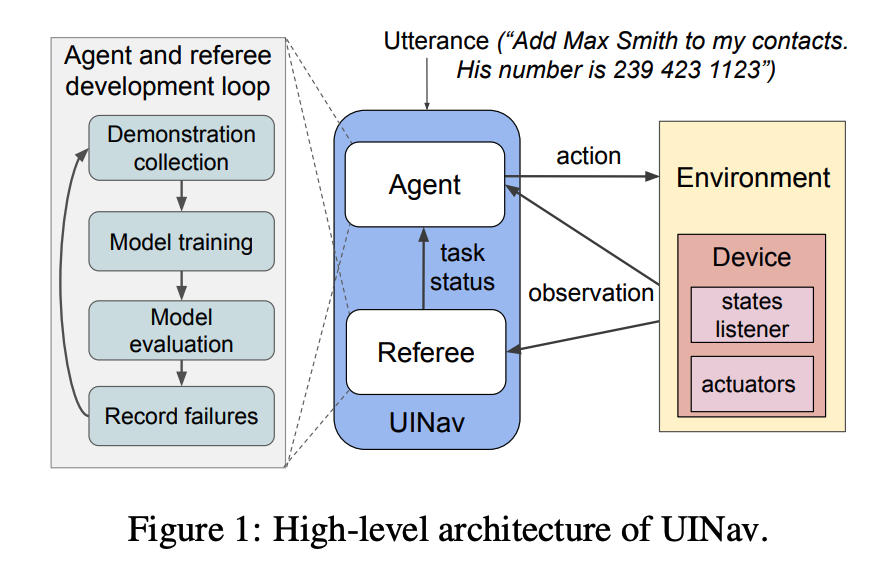
UINav
Google research publication - UINav: A practical Approach to Train On-Device Automation Agents
A demonstration-based approach to train automation agents that fit mobile devices, yet achieving high success rates with modest number of demonstrations.
What are UI automation agents
Agents that can execute human tasks by interacting directly with the UI of a running application. (Liu et al., 2020; Humphreys et al., 2022)
Existing approaches to UI automation
UI scripts
Enterprises love this to automate business workflows. (UIPath, 2023)
AI-based agents
Imitation learning and reinforcement learning have been tried, but their synthetic test environments are simple and they need large amount of demonstrations.
Transformers and pre-trained large language models (LLMs) have been tried, but they are resource-consuming.
Proposed UINav
UINav finds tradeoff among accuracy, generalizability, and computational costs.
Demonstrations
By ‘demonstration-based’, meaning few shots.
Immediate feedback on failing tasks is provided through a referee model during demonstrations collection, will ask for additional demonstrations. The referee model is trained to predict whether a task is successfully completed.
How to deal with system delays and dynamic UI
- Macro actions. This is a bunch of lower-level operations composed as a small program. This brings smaller agents’ state space (about demonstrations) and faster operating speed.
- Demonstration augmentation. Human demonstrations are augmented by randomizing non-critical UI elements to increase their diversity.
- Utterance masking. Variable sub-strings in utterances are abstracted out.
Agent’s neural network architecture
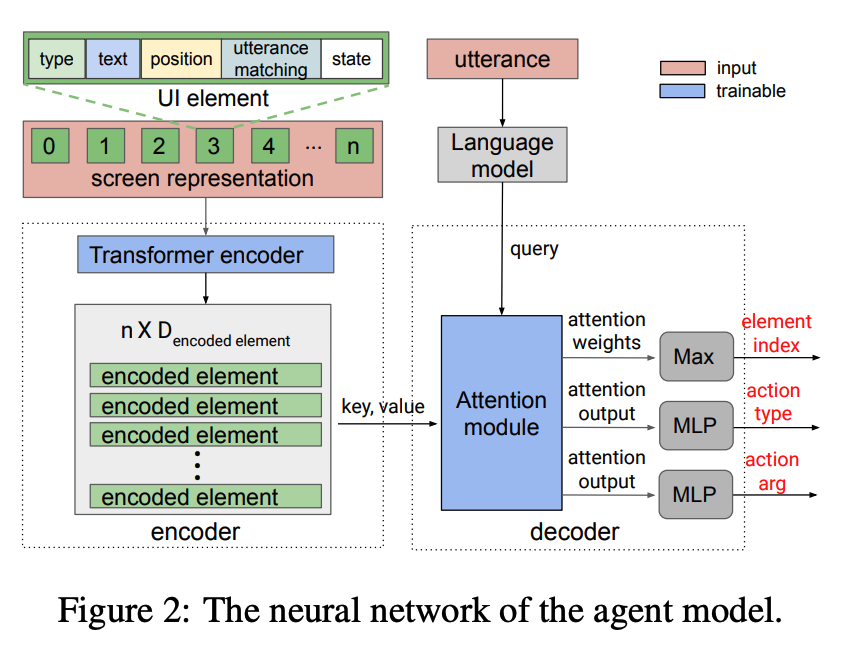
The screen representation comes from two source: a)description of attributes [type, text, on-screen position, utterance matching, state], b)representation generated from raw pixels using screen understanding techniques (Chen et al., 2020; Wu et al., 2021; Zhang et al., 2021) [icon detection, text recognition, a tree-structured representation of UI (eg Android accessibility tree)].
Input 1: a set of UI elements. Input 2: an utterance.
Output predicted by decoder: which action to perform [ready-to-act element, action type, action arguments]. Actions has two kinds: a)element actions, b) global actions.
Utterance masking
{Search for tiktok in Google} → replace the specific instance before feeding to agents {Search for placeholder in Google}, while tiktok is saved for later use in performing this task.
Demonstration augmentation
Limit the number of required demonstrations for efficiency. Make non-critical UI elements to be more tolerant to UI changes, by either i)replacing the embedding of their text labels with random vectors, or ii)by adding random offsets to the four scalars of their bounding boxes (ie to randomize both the element’s position and size).
Implementation
Upon Android platform.
Dataset: MoTIF; in-house one.
Agent & referee models are implemented in TensorFlow. Both of them are trained to stable off-device firstly (Python API of TensorFlow), then converted to .tflite (TensorFlowLite) and deploy on device. Both of them use SmallBERT: L-2_H-128_A-2 (the smallest model). No quantization during the conversion of .tflite.
Rely on an in-house built companion Android app to extract screen representations and to perform macro actions.
Off-device mode: Utilize AndroidEnv (Toyama et al., 2021) to communicate between the companion app and the learning environment (models). On-device mode: models interact with the companion app directly. Screen representations and macro actions are designed as model-agnostic.
Macro actions
2021 Learning UI Navigation through demonstrations composed of macro actions.
IconNet
Google search blog: Improving Mobile App Accessibility with Icon Detection
A vision-based object detection model, automatically detecting icons on the screen, agnostic to the underlying structure of the app (ie app-level accessibility trees), launched as part of the Voice Access.
- On-device model architecture is developed based on CenterNet, extracting features from input images & predicting bounding box centers and sizes. Server-side model architecture: backbone Hourglass, with compression → neural architecture search (NAS) → + Fine-Grained Stochastic Architecture Search (FiGS).
- Dataset: in-house.
Screen Representation
Chen et al., 2020
Object detection for graphical user interface: old fashioned or deep learning or a combination? Keywords: Android, object detection, user interface, deep learning, computer vision
- Dataset: Rico
- A large-scale empirical study of 7 GUI element detection methods. Old-fashioned: REMAUI; Xianyu; Deep learning: Faster RCNN (two stage style, anchor-box based); YOLO V3 (one stage style, anchor-box based); CenterNet (one-stage, anchor-free); For GUI text detection: OCR tool, Tesseract; scene text detector, EAST.
- A GUI-specific old-fashioned method for non-text GUI element detection, adopts a top-down coarse-to-fine strategy. Integrated with a mature deep learning model for GUI text detection, ie EAST.
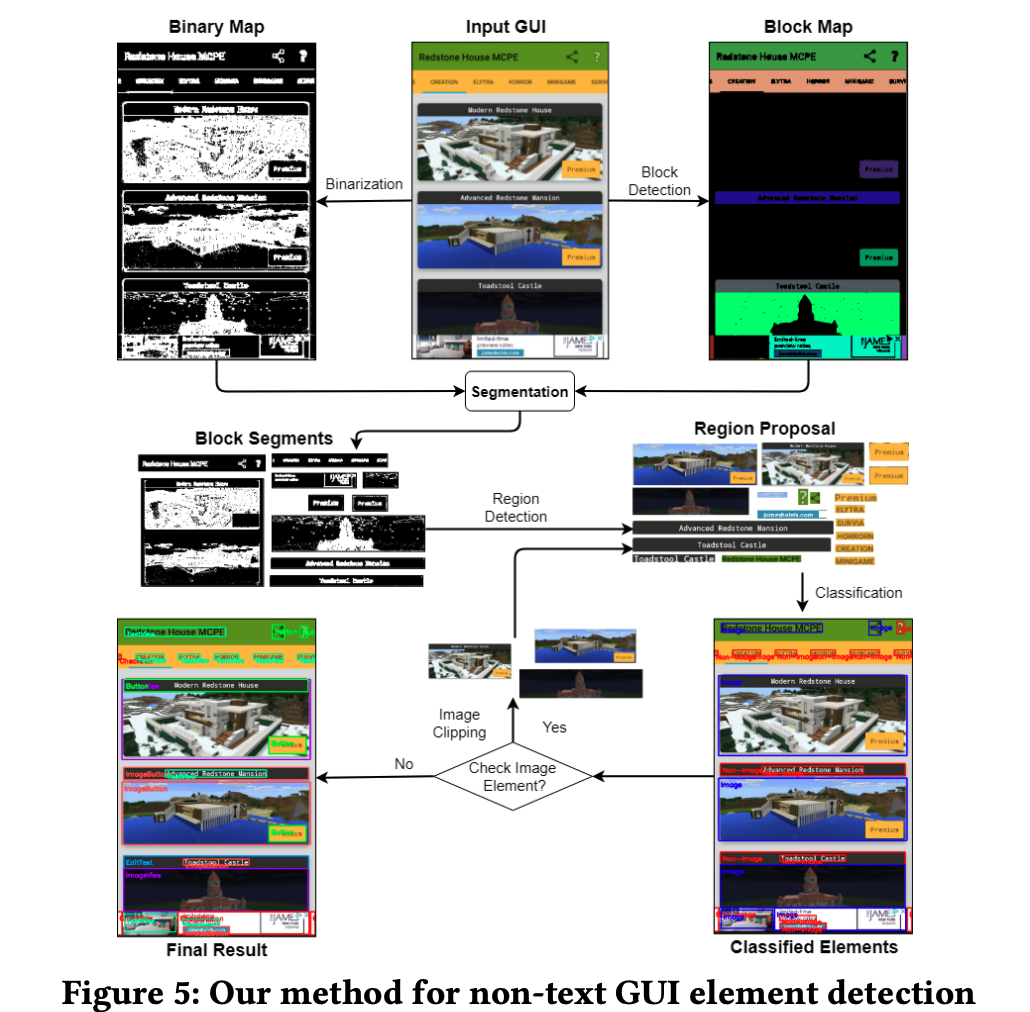
Object detection for graphical user interface: old fashioned or deep learning or a combination?
Wu et al., 2021
Screen Parsing: Towards Reverse Engineering of UI Models from Screenshots Keywords: user interface modeling, ui semantics, hierarchy prediction
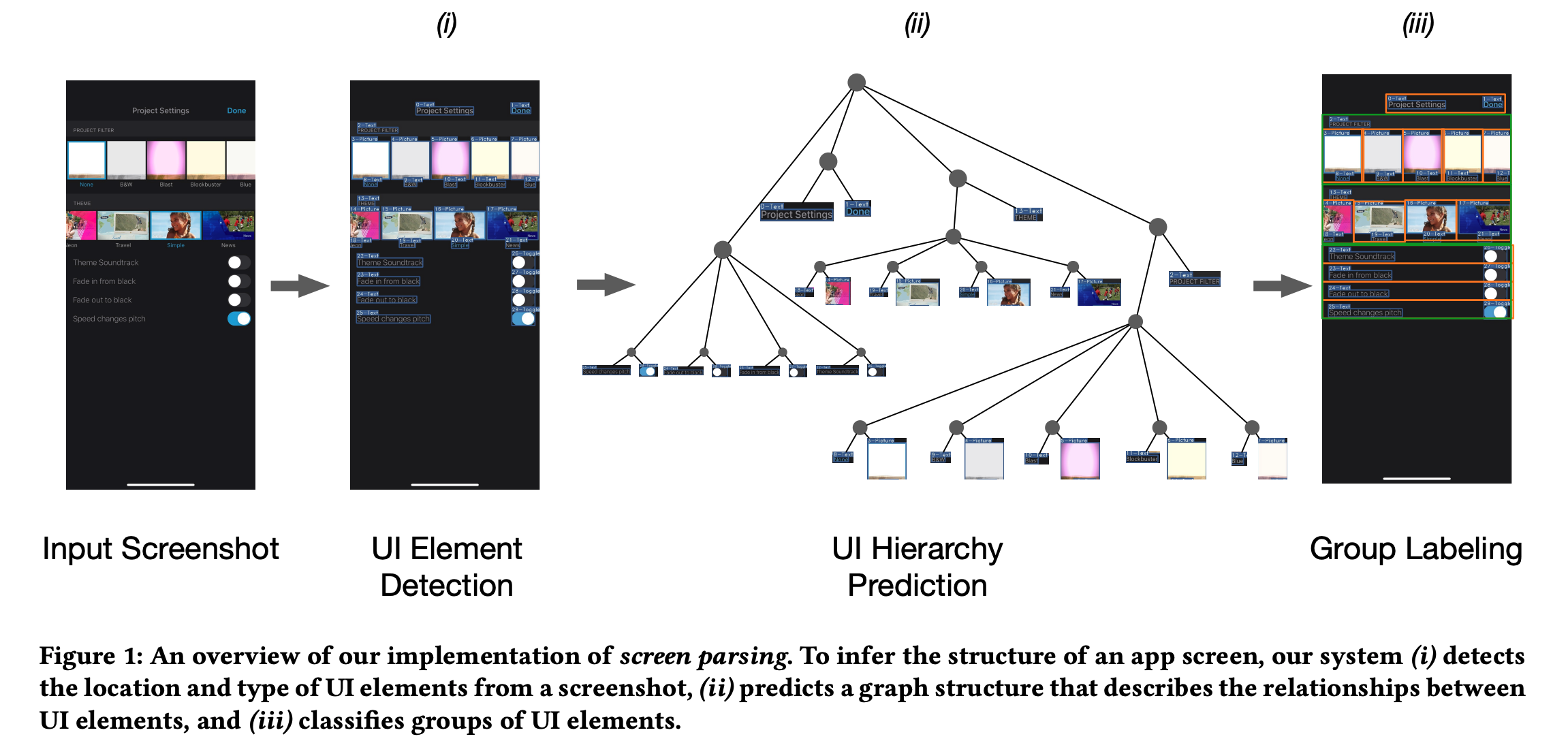
Screen Parsing: Towards Reverse Engineering of UI Models from Screenshots
Dataset: Rico, internal AMP dataset
Model Architecture
One of the applications, generating ui code from a screenshot.
Workflow: input a screenshot → a ui hierarchy → depth-first traversal, on visitor pattern (abstract syntax trees) → generate code, by visitor function → a SwiftUI control for each leaf node & a SwiftUI container for each intermediate node → manual map of [node types in screen parser tree, SwiftUI views] → add labels, by OCR → heuristics on color theme → code generation, without style information (eg text size, element color).

Screen Parsing: Towards Reverse Engineering of UI Models from Screenshots
Model architecture
A standard object detection model, extracting UI elements in a screen with their parameters, specifically a Faster-RCNN with a ResNet-50 backbone. A top-down transition-based parser, constructing UI hierarchy & decoding.
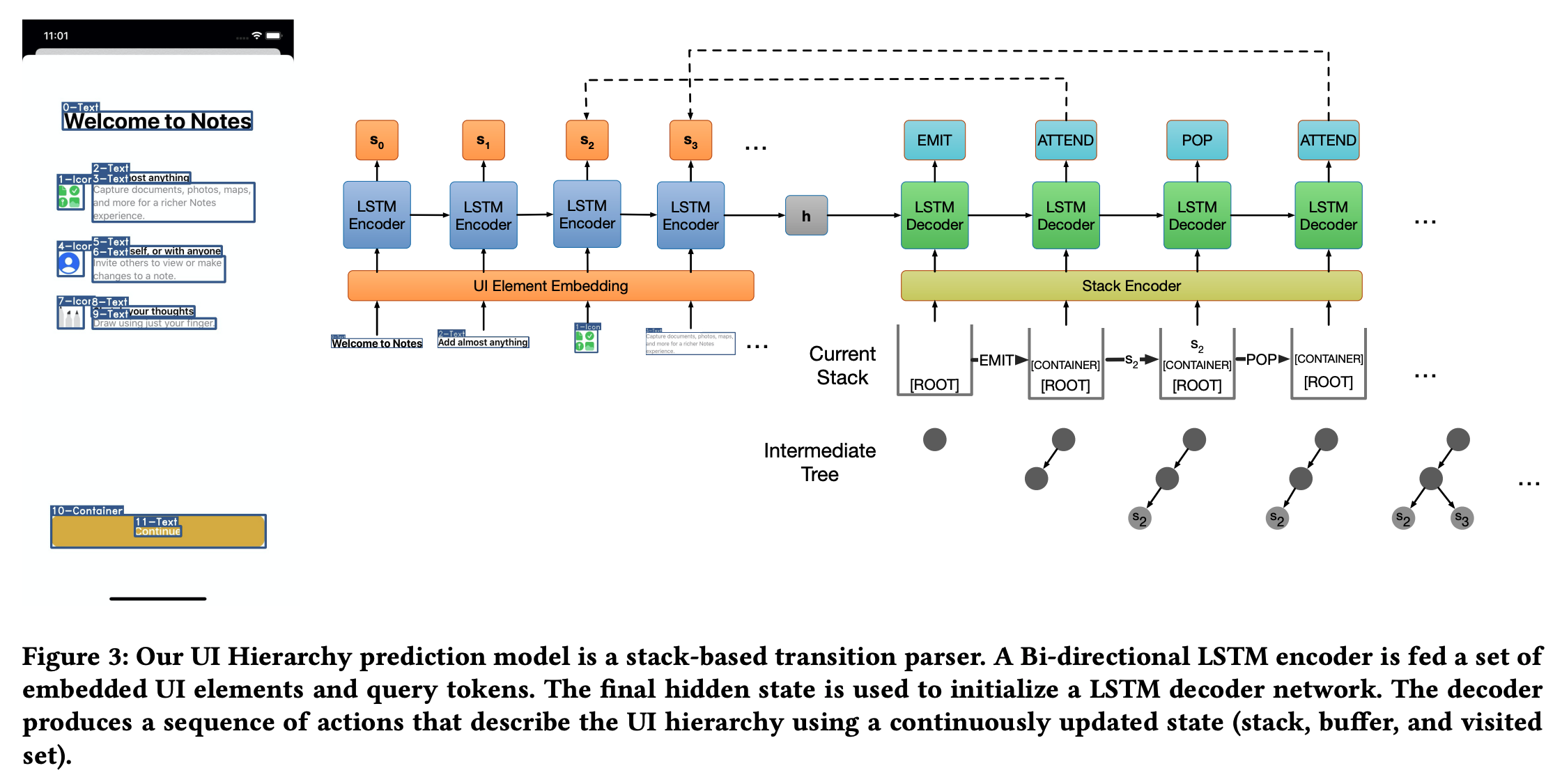
Screen Parsing: Towards Reverse Engineering of UI Models from Screenshots
Zhang et al., 2021
Screen Recognition: Creating Accessibility Metadata for Mobile Applications from Pixels Human—centered computing → Accessibility technologies Keywords: mobile accessibility, accessibility enhancement, ui detection
Dataset: in-house 77637 screens (from 4068 iPhone apps), annotation including segmentation (bounding box) and classification (12 + other types).
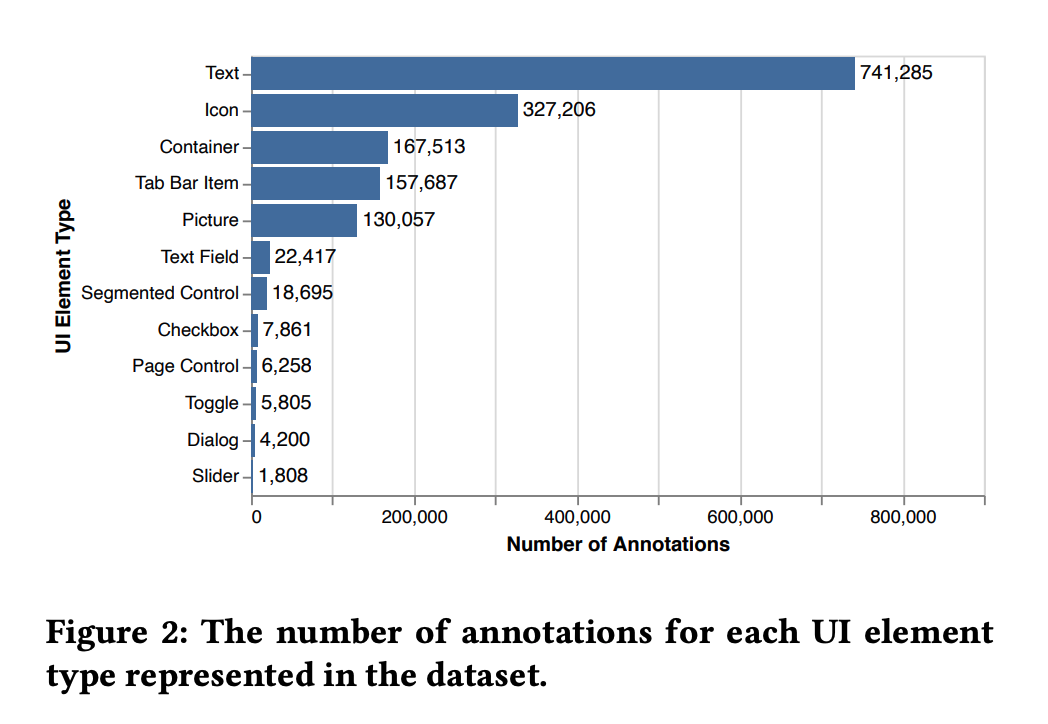
- Analysis includes error rate, distribution of 12 UI types (class-imbalanced), discrepancies between annotations and UI element metadata for each screen (lack of accessibility labels for accessibility service).
A on-device object detection model
Heuristics method, correcting detections, eg provide UI grouping and ordering, with people with visual impairments. Additional model method, eg recognize UI content, state, interactivity.
Measurement using Mean Average Precision (71.3%)
Screen Recognition, generating accessibility metadata for iOS VoiceOver (iOS screen reader).
User study on inaccessible apps
Workflow: i)data collection; ii)data annotation; iii)ui detection model; iv)improved user experience; v)integration with screen reader.
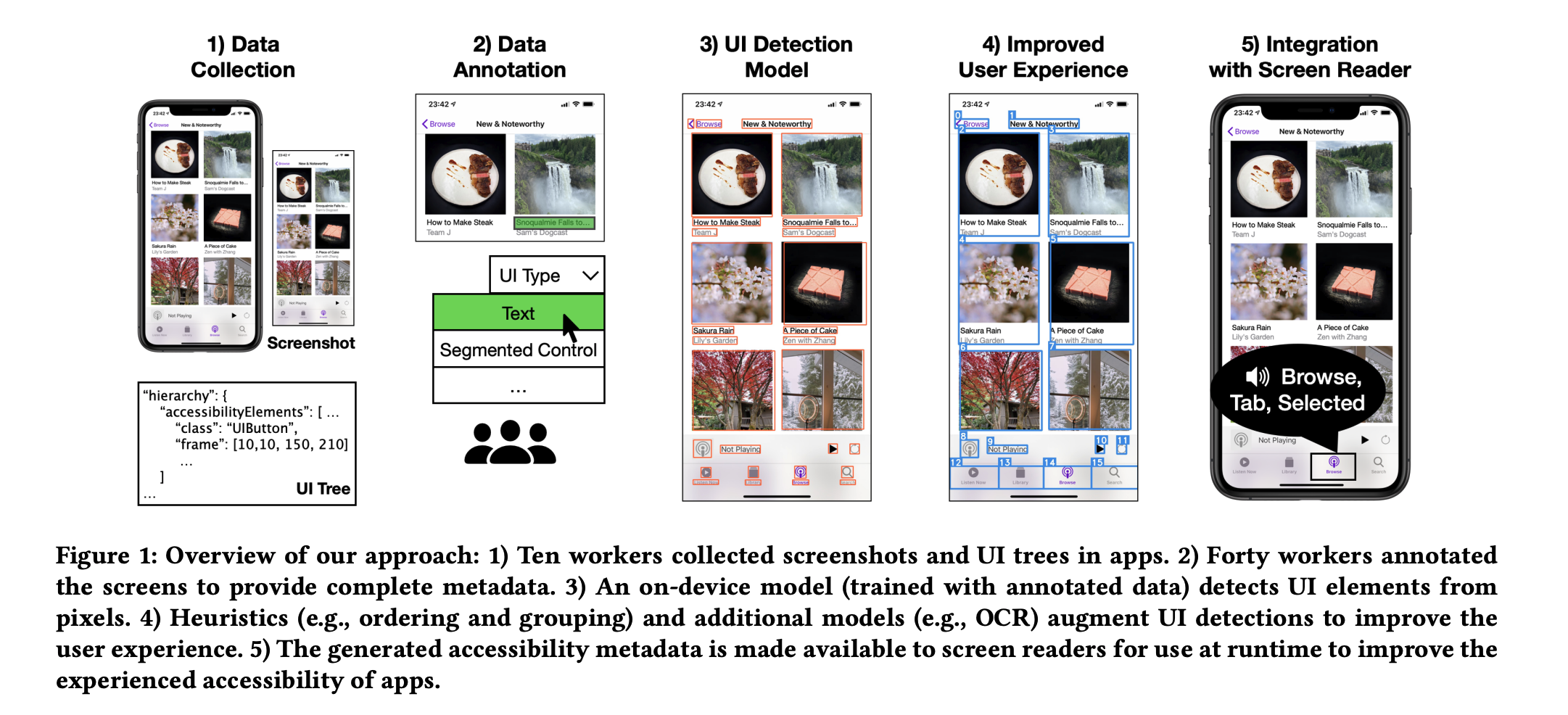
Screen Recognition: Creating Accessibility Metadata for Mobile Applications from Pixels
Related applications: interface augmentation & remapping; GUI testing; data-driven design for GUI search; prototyping; generating UI code from existing apps to support app development; GUI security. Automate accessibility metadata generation. Related works: pixel-based interpretation of interfaces; traditional image processing methods; deep learning models, Pix2Code, CNN-RNN; object detection models: GalleryDC, YOLOv2
Model architecture
Faster R-CNN, Mask R-CNN. TuriCreate Object Detection toolkits. Single Shot MultiBox Detector (SSD).
Backbone: MobileNetV1. Feature extractor: Feature Pyramid Network (FPN).
Data augmentation on under-represented UI types. Apply class-balanced loss function to give more weight for under-represented UI types.
Training devices: 4 Tesla V100 GPUs for 20 hours (557 k iterations).
Post-processing on filtering out duplicate detections: i)Non-Max Suppression; ii)different confidence thresholds applied on each UI type.
Improvement on raw UI detection results
A) Find missing UI elements and remove extra detections.
B) Recognize rich UI content in Text, Icon, Picture.
C) Determine UI selection state.
D) Determine UI interactivity, eg swipe up or down for a page control, double tap to edit.
E) Group elements for efficient navigation.
- Heuristics based on UI types , sizes, spatial relationships on the screen, ie if-else rules.
F) Infer navigation order.
- OCR XY-cut page segmentation algorithm.
Future work
Improve the heuristics. Apply on Android. Apply on desktop, Web. Learning structured information in app view hierarchy in addition to pixels information (as well as on-the-fly, out-of-accessibility-mode potential). Incorporate the model into developer tools to help developers. Serve in accessibility APIs. More universal model, resilient to aesthetic qualities and interactions changes.
Datasets
Chen et al., 2018
From UI Design Image to GUI skeleton: A Neural Machine Translator to Bootstrap Mobile GUI Implementation.
Implement an Android UI data controller, Stoat, to automatically collect 185277 pairs of [UI images, GUI skeletons], from 5042 Android apps.
Rico
2017 Rico: A mobile app dataset for building data-driven design applications. Website link.
UI corpus with 72k android UI screens minded from 9.7K android apps. [A screenshot image, a view hierarchy of a collection of UI objects, a set of properties of UI objects (name, type, bounding box position) ].
Training image classification models to recognize icons.
MoTIF
2022 A dataset for interactive vision language navigation with unknown command feasibility. Github link.
A sample includes the natural language command (ie task), app view hierarchy, app screen image, action coordinates for each time step.
Seq2act
2020 Mapping Natural Language Instructions to Mobile UI Action Sequences. Github link.
PixelHelp
Pixel Phone Help pages, instructions for performing common tasks on Google Pixel phones.

AndroidHowTo
32436 data points from 9893 unique How-To instructions.
RicoSCA
Filter based on Rico. 295476 single-step synthetic commands for operating 177962 different target objects across 25677 Android screens.
Object Detection
CenterNet
2019 CenterNet: Keypoint Triplets for Object Detection
Faster R-CNN
2015 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
YOLOv3
2018 YOLOv3: An Incremental Improvement
Further Readings
Survey on Mobile Accessibility
- 2017 Epidemiology as a Framework for Large-Scale Mobile Application Accessibility Assessment